MICHEL CHARTIER, étudiant
Ce texte est d’une version modifée d’un travail a été réalisé à l’EBSI, Université de Montréal, dans le cadre du cours ARV1050 – Introduction à l’archivistique donné au trimestre d’automne 2016 par Daniel Ducharme.
Dans un billet précédent, nous avons posé la problématique de la conservation des documents en soulignant la possibilité de recourir à l’ADN comme moyen éventuel de conservation. Dans ce billet, sans aller trop loin dans les détails, nous présenterons, en ordre chronologique, quelques-unes des méthodes qui ont été élaborées dans le but de consigner de l’information au moyen d’ADN.
Clelland et collègues (1999)
Cette première méthode n’a pas été mise au point dans le but d’archiver des données. Il s’agit néanmoins de l’une des premières à utiliser de l’ADN pour coder des messages (l’information), et c’est pourquoi nous l’abordons ici.
Selon Clelland, Risca et Bancroft (1999), elle s’inspire de la stéganographie, technique développée par le professeur Zapp et utilisée durant la Deuxième Guerre mondiale par les espions allemands pour transmettre des messages secrets. Elle consistait à photographier une page dactylographiée, à réduire considérablement la photo pour ainsi obtenir un « micropoint », puis à coller celui-ci sur un point (signe de ponctuation) dans une lettre anodine.
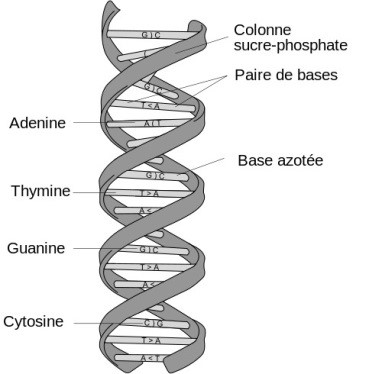
Ces chercheurs ont utilisé la technique stéganographique pour coder un message de type textuel dans un échantillon d’ADN et pour dissimuler ce dernier dans un micropoint. Le message est codé dans un brin d’ADN au moyen d’une clé de chiffrement, où les lettres de l’alphabet, les nombres de 1 à 9 et certains signes de ponctuation correspondent chacun à un triplet de bases azotées distinct (p. ex., A=CGA, B=CCA et ainsi de suite). Le message est associé à des séquences d’amorces, lesquelles servent à synthétiser le brin complémentaire d’ADN, et donc à « lire » le message. Une minuscule gouttelette de solution contenant 225 nanogrammes d’ADN humain, y compris le brin contenant le message caché, est ensuite versée sur un point imprimé sur du papier filtre. Dans cette expérience, des micropoints produits de cette manière ont été fixés à des points dans une lettre, puis celle-ci a été envoyée par l’entremise des services postaux des États-Unis. Le destinataire, qui connaissait au préalable les séquences d’amorces utilisées et détenait la clé de chiffrement, a fait appel à la technique d’amplification en chaîne par polymérase (PCR) pour amplifier l’ADN, ce qui lui a permis de lire et de décoder le message suivant, qui se voulait un clin d’œil à l’Histoire : « June 6 invasion: Normandy ».
Pour nous, l’intérêt de cette méthode réside dans le fait qu’elle a montré qu’il était possible de consigner de l’information de type alphanumérique sous forme d’ADN.
Il convient de mentionner que deux de ces chercheurs, en collaboration avec d’autres collègues, ont amélioré la technique en vue de l’utiliser comme moyen d’archivage en bonne et due forme (Bancroft, Bowler, Bloom et Clelland, 2001). La manière de coder de l’information (texte ou autre) dans l’ADN est semblable à celle utilisée dans la technique des micropoints, mais de nouveaux concepts sont introduits : l’ADN contenant l’information consignée est surnommé ADNi, et une « clé » constituée de multiples amorces sert à décoder l’information en question. Les techniques de la PCR et du séquençage permettent d’amplifier et d’analyser les séquences d’ADN en vue d’y extraire l’information. En outre, les chercheurs entrevoient la possibilité de conserver jusqu’à plusieurs milliers d’échantillons d’ADNi dans de petits dispositifs appelés microréseaux, ou puces à ADN, de la taille d’un timbre-poste, dont la capacité d’archivage équivaudrait à plusieurs dizaines de livres de type roman.
Ailenberg et Rotstein (2009)
Ces chercheurs sont parvenus à consigner divers types de données dans de l’ADN en utilisant tous les caractères présents sur un clavier d’ordinateur standard, ce qui ouvre davantage de possibilités comparativement à la technique précédente. Le codage de l’information repose ici aussi sur l’attribution de bases azotées à chaque caractère. Chaque caractère possède son propre « code » (appelé « codon » par les auteurs), qui correspond à un segment de la molécule d’ADN constitué d’un nombre et d’un ordre précis de bases azotées. Pour définir les codons, les chercheurs se sont inspirés de la méthode dite « de Huffman », laquelle a été mise au point par un chercheur du même nom dans le but de construire des codes composés de texte chiffré à l’aide d’un nombre minimal de symboles (voir Smith, Fiddes, Hawkins et Cox, 2003), permettant ainsi de simplifier le plus possible le codage des données. À leur tour, les codons d’ADN sont associés à des amorces spécialement conçues en vue de réduire la possibilité d’erreurs et d’accroître l’efficacité lors de la « lecture » de l’information consignée sur support ADN. Bien entendu, cette technique repose sur toute une série de manipulations en laboratoire, et de multiples produits et dispositifs sont nécessaires pour synthétiser l’ADN en question, mais les auteurs insistent sur le fait que l’extraction de l’information peut être réalisée de manière automatisée.
Grâce à cette technique, et en définissant des règles pour chaque type de données, Ailenberg et Rotstein ont pu synthétiser de l’ADN contenant une partie du texte de la comptine Mary had a little lamb et les notes de musique correspondantes. Ils ont aussi codé une « image », c’est-à-dire des coordonnées qui, lorsque décodées et transposées sur un diagramme bidimensionnel, permettent de recréer au moyen de formes géométriques très simples (cercles, rectangles, lignes) l’agneau de Mary.
Goldman et collègues (2013)
Grâce à la méthode qu’ils ont mise au point, Goldman et coll. (2013) ont pu consigner une quantité d’information beaucoup plus élevée que dans le cas des autres techniques élaborées jusqu’alors. Le codage des données s’effectue essentiellement en trois étapes. L’information est d’abord convertie sous forme numérique, soit en code binaire. Celui-ci est ensuite converti mathématiquement selon un système ternaire (0, 1 et 2) qui remplace chaque octet (ou caractère) par un « trit » composés de cinq ou six chiffres. Enfin, un appareil permet de synthétiser des chaînes d’ADN dans lesquelles chaque trit est remplacé par l’un des trois nucléotides qui diffèrent de celui utilisé pour le trit précédent. Bref, la procédure est assez complexe, quoique les résultats obtenus par ces chercheurs soient prometteurs.
Goldman et ses collègues ont mis leur méthode à l’essai en codant l’information tirée de cinq fichiers informatiques de formats différents (ASCII, PDF, JPEG et MP3), dont les 154 sonnets de Shakespeare et un court extrait du fameux discours de Martin Luther King intitulé « I have a dream », dans des chaînes d’ADN synthétique. Au total, ils ont consigné l’équivalent de 739 kilo-octets de données réparties dans plus de 153 000 chaînes d’ADN, chacune comportant 117 nucléotides. Fait notable, ils ont réussi à séquencer les morceaux d’ADN et à reconstituer le contenu des fichiers d’origine sans qu’aucune erreur ne s’y insère. Les chercheurs indiquent également que leur méthode pourrait, en théorie, servir à l’archivage de données à grande échelle et à long terme.
Il importe de souligner que les techniques présentées dans le présent travail (de même que celles que nous n’avons pas abordées) ne peuvent, pour le moment, être mises en œuvre de manière concrète, et ce, pour diverses raisons. D’une part, les coûts associés à la synthèse de l’ADN sont encore très élevés (Extance, 2016). D’autre part, la technologie actuelle ne permet pas de synthétiser de l’ADN à une échelle et à une vitesse suffisamment grandes pour concurrencer les méthodes d’archivage numérique existantes (par exemple, les supports magnétiques et optiques). Mais les acteurs de ce domaine de recherche semblent optimistes; le savoir et les technologies évoluent rapidement, de sorte que l’archivage de données sur support ADN pourrait être une pratique courante dans un avenir pas si lointain.
Conclusion : incidence sur la pratique archivistique
Si elles étaient adoptées, quelles pourraient être les répercussions de ces méthodes sur la pratique archivistique? Les futurs archivistes seraient-ils appelés à devenir des spécialistes de la biologie moléculaire afin de pouvoir maîtriser les concepts et les techniques qui sous-tendent la consignation d’information sur support ADN ?
Au fil du temps, les archivistes ont dû adapter leurs pratiques et acquérir de nouvelles connaissances et habiletés en fonction, notamment, de l’évolution des supports documentaires. À cet égard, le dernier siècle a été particulièrement mouvementé, si l’on peut dire, puisqu’il a vu l’apparition des premiers ordinateurs, puis le développement rapide de l’informatique et des outils technologiques connexes. Ces nouveaux moyens, qui permettent à la fois de produire et de consigner de l’information, ont bouleversé le travail des archivistes. Ceux-ci ont ainsi eu à se familiariser avec ces technologies et en sont venus à les utiliser à leur avantage dans le cadre de leurs activités.
Rien n’indique que, si les méthodes susmentionnées en venaient à s’imposer pour l’archivage et la conservation à long terme des données, les archivistes ne seraient pas en mesure de s’y adapter. Peut-être que des archivistes spécialisés seraient formés en vue du traitement approprié de l’information consignée sur support ADN. Du point de vue strictement pratique, le codage des données sous forme d’ADN faisant appel à des procédures largement (voire entièrement) automatisées, les archivistes seraient surtout amenés à mettre leurs connaissances technologiques à niveau, les dispositifs utilisés pouvant s’apparenter à des ordinateurs conçus pour accomplir des tâches très précises. À cette mise à niveau pourrait s’ajouter une formation visant à inculquer la théorie et les concepts fondamentaux de la biologie moléculaire. Est-il réaliste de penser que les archivistes pourront tirer profit de ces éventuelles méthodes d’archivage de l’information? Les archivistes modernes portent déjà plusieurs chapeaux : ils sont à la fois historiens, gestionnaires, informaticiens (etc.) ou, du moins, possèdent certaines des compétences propres à ces spécialités. À la lumière de ce constat, c’est par l’affirmative que nous répondons à cette question.
Sources consultées
- ADN. (2012). Dans Encyclopédie de l’Agora. Repéré à http://agora.qc.ca/dossiers/ADN
- Ailenberg, M. et Rotstein, O. D. (2009). An improved Huffman coding method for archiving text, images, and music characters in DNA. BioTechniques, 47(3), 747-754.
- Bancroft, C., Bowler, T., Bloom, B. et Clelland, C. T. (2001). Long-Term Storage of Information in DNA. Science, 293(5536), 1763-1765.
- Church, G. M., Gao, Y. et Kosuri, S. (2012). Next-Generation Digital Information Storage in DNA. Science, 337(6102), 1628.
- Clelland, C. T., Risca, V. et Bancroft, C. (1999). Hiding messages in DNA microdots. Nature, 399(6736), 533-534.
- Conway, P. (1996). Preservation in the Digital World (Publication no 62). Repéré sur le site du Council on Library and Information Resources : https://www.clir.org/pubs/reports/reports/conway2/index.html
- Cox, J. P. L. (2001). Long-term data storage in DNA. Trends in Biotechnology, 19(7), 247-250.
- Eternal 5D data storage could record the history of humankind. (2016). Repéré à http://www.southampton.ac.uk/news/2016/02/5d-data-storage-update.page
- Exaoctet. (2000). Dans Le grand dictionnaire terminologique. Repéré à http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8873628
- Extance, A. (2016). Digital DNA – Could the molecule known for storing genetic information also store the world’s data? Nature, 537(7618), 22-24.
- Goldman, N., Bertone, P., Chen, S., Dessimoz, C., LeProust, E. M., Sipos, B. et Birney, E. (2013). Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature, 494(7435), 77-80.
- Numérique. (2003). Dans Le grand dictionnaire terminologique. Repéré à http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8360889
- Qu’est-ce que l’ADN? (s. d.). Repéré à http://www.lps.ens.fr/recherche/biophysique-ADN/dna1.html#rappels
- Smith, G. C., Fiddes, C. C., Hawkins, J. P. et Cox, J. P. L. (2003). Some possible codes for encrypting data in DNA. Biotechnology Letters, 25(14), 1125-1130.
- Un disque de verre pour stocker les données pour l’éternité (ou presque). (2016). Repéré à http://www.liberation.fr/futurs/2016/02/21/un-disque-de-verre-pour-stocker-les-donnees-pour-l-eternite-ou-presque_1434895
- Waters, D. et Garrett, J. (1996). Preserving Digital Information : Report of the Task Force on Archiving of Digital Information. Washington, DC : The Commission on Preservation and Access.