MICHEL CHARTIER, étudiant
Ce texte est d’une version modifée d’un travail a été réalisé à l’EBSI, Université de Montréal, dans le cadre du cours ARV1050 – Introduction à l’archivistique donné au trimestre d’automne 2016 par Daniel Ducharme.
L’enjeu de la conservation
Pendant de nombreux siècles, et après avoir succédé à d’autres matières, le papier a été le principal support utilisé pour la consignation de l’information (surtout sous forme de texte, mais aussi d’images). Au papier se sont ajoutés, depuis le 19e siècle, d’autres supports, l’évolution de la technologie ayant permis de développer de nouvelles façons d’obtenir, puis de consigner l’information (par exemple, sous forme d’enregistrements sonores ou vidéo). Cette évolution s’est accélérée et a mené, dans la deuxième moitié du 20e siècle, à la création de techniques dites numériques, soit celles permettant « la production, le stockage et le traitement d’informations sous forme binaire » [c’est-à-dire des 1 et des 0] (Numérique, 2003). On parle souvent, dans ce contexte, de « révolution numérique », l’avènement de ces techniques ayant entraîné des changements importants et durables dans plusieurs aspects de la vie quotidienne, tant à l’échelle individuelle qu’à l’échelle sociétale. Au cours de l’Histoire, les archivistes, qui ont été des témoins privilégiés de l’évolution des documents, ont vu leur rôle évoluer en fonction de l’accroissement de la masse d’information produite par les individus et les organisations et de la diversification des supports utilisés pour la consigner.
L’accroissement exponentiel de l’information générée par les activités humaines et la diversification des supports créent par ailleurs un paradoxe des plus intéressants : tandis que notre capacité de consigner l’information s’est accrue avec le temps, la longévité des supports utilisés pour la conserver tend à diminuer (Conway, 1996; dans cet article, l’auteur qualifie cette situation de « dilemme », mais nous sommes d’avis que le terme « paradoxe » la décrit plus correctement). Ainsi, l’enjeu de la conservation à long terme de l’information consignée, qui concerne tous les types de supports documentaires, se pose avec encore plus d’acuité dans le cas des documents numériques. Bien qu’ils offrent l’avantage de pouvoir contenir de vastes quantités de données, les supports numériques présentent aussi plusieurs désavantages, dont les suivants : ils sont caractérisés par leur fragilité et par l’obsolescence rapide des technologies (matériel, logiciels) utilisées pour y consigner l’information (Waters et Garrett, 1996).
Afin de contourner les difficultés associées aux supports numériques, des chercheurs ont tenté de mettre au point des solutions de rechange plus stables qui offrent des capacités d’archivage de données exceptionnelles tout en assurant la conservation à très long terme de ces mêmes données. La dernière en date est celle consistant à archiver des données pentadimensionnelles (5D) dans un petit disque de verre nanostructuré de la taille d’une pièce de monnaie (Eternal 5D data storage, 2016). Cette technique, développée par des chercheurs de l’université de Southampton (Royaume-Uni), fait appel à un laser à impulsions ultracourtes pour la gravure des données à même le verre. Chaque disque a une capacité de stockage de 360 téraoctets (soit 3000 fois la capacité d’un disque Blu-Ray. Un disque de verre pour stocker les données peut résister à des températures allant jusqu’à 1000 °C et a une durée de vie théorique de 13,8 milliards d’années à une température ne dépassant pas 190 °C. De l’avis des chercheurs, cette technologie pourrait être fort utile aux organisations détenant de vastes archives, pourvu bien sûr qu’elles aient accès à l’équipement nécessaire pour la gravure (laser) et la lecture (microscope optique et polariseur) des disques.
L’une des autres solutions mises à l’essai fait l’objet du présent travail : il s’agit de l’archivage de données à l’aide d’acide désoxyribonucléique, mieux connu par son sigle : ADN.
L’ADN, support de l’information génétique
L’ADN est une molécule que l’on retrouve dans les cellules de tous les êtres vivants. On peut la représenter, d’une manière extrêmement simplifiée, sous la forme d’une échelle : les montants de l’échelle correspondent aux deux brins parallèles de la molécule d’ADN, et chaque barreau correspond à deux bases azotées liées l’une à l’autre (Encyclopédie de l’Agora, 2012; voir la figure 1). Les deux brins de cette « échelle » s’enroulent l’un autour de l’autre; la structure torsadée qui en résulte est dite « en double hélice » (Qu’est-ce que l’ADN?, s. d.). Chaque moitié de l’échelle est composée d’une succession d’éléments appelés nucléotides. Le nucléotide est constitué à son tour d’un groupement phosphate, d’un glucide et d’une base azotée (celle-ci formant l’une des deux moitiés d’un « barreau ») (Encyclopédie de l’Agora, 2012). On dénombre quatre bases azotées, soit l’adénine (A), la cytosine (C), la guanine (G) et la thymine (T), A s’appariant toujours avec T, et C avec G. Ces paires de bases azotées assurent la complémentarité des deux moitiés de la molécule d’ADN (Qu’est-ce que l’ADN?, s. d.). La succession particulière des nucléotides le long d’une molécule d’ADN est donc le support sur lequel est consignée l’information génétique.
L’ADN en tant que support documentaire?
La molécule d’ADN peut être considérée comme une sorte de « langage », l’information qu’elle contient devant être décodée par la cellule pour la synthèse des protéines dont elle a besoin, un peu à la manière d’un livre de recettes (Qu’est-ce que l’ADN?, s. d.). Vu sous cet angle, il n’est peut-être pas surprenant que certains chercheurs en soient venus à envisager la possibilité d’utiliser l’ADN pour y consigner de l’information autre que génétique.
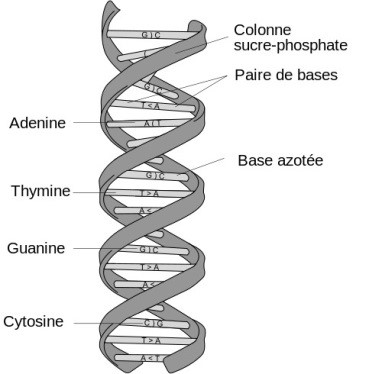
Représentation schématisée d’un segment de molécule d’ADN. Image tirée de Wikipédia (« Acide désoxyribonucléique », repéré à https://fr.wikipedia.org/wiki/Acide_désoxyribonucléique)
Comme le souligne Cox (2001), l’ADN présente d’excellentes qualités pour le stockage de données :
- Son usage à cette fin a fait ses preuves (la vie existant sur Terre depuis au moins 3,5 milliards d’années) ;
- Les conditions s’y prêtant, il peut être conservé sur des périodes de l’ordre de millions d’années ;
- Il a la capacité de se reproduire lui-même ;
- Sa séquence de nucléotides peut contenir une quantité considérable d’information.
La « densité de mémorisation » de l’ADN est effectivement très élevée : en théorie, on pourrait y coder jusqu’à 2 bits par nucléotide, soit environ 455 exaoctets (ou 455 milliards de milliards d’octets, selon la définition d’exaoctet donnée dans Le grand dictionnaire terminologique [2000], ce qui équivaut, après conversion, à 455 millions de téraoctets, si l’on veut comparer avec le disque de verre nanostructuré mentionné précédemment) par gramme d’ADN à simple brin (Church, Gao et Kosuri, 2012).
Dans un billet ultérieur, sans aller trop loin dans les détails, nous présenterons, en ordre chronologique, quelques-unes des méthodes qui ont été élaborées dans le but de consigner de l’information au moyen d’ADN. Les sources consultées seront également mentionnées dans ce billet.
merci pour cet article
vraiment une trés bonne initiative à encouragé dans le future proche